
Project Oriented Problem Based Learning (POPBL 1) - Detección de ataques avanzado

Este apartado describe el primer proyecto POPBL de la universidad de Mondragón para el máster en Análisis de datos, Ciberseguridad y Cloud Computing. En este caso, fue un tema propuesto por el profesorado.
El proyecto combina las ramas del análisis de datos, ciberseguridad y computación en la nube en un gran proyecto común. El objetivo general fue crear una infraestructura cloud (AWS) con microservicios que simulan un entorno de fabricación industrial junto con una API Gateway (HAProxy y Consul para el Discovery) con el fin de permitir peticiones HTTP a los microservicios.
Al mismo tiempo, la instalación de honeypots (Cowrie y Dionaea) fue útil para la detección y recogida de información de diferentes ataques (Elastic stack). Con dicha información fuimos capaces de crear un modelo de detección de anomalías (clustering o clasificación).
Finalmente creamos un dashboard (Kibana) con el fin de conocer más el perfil de nuestros atacantes.
Me gustaría destacar diferentes herramientas, que quizás puedan quedar en "un segundo plano" ya que no influye directamente en el funcionamiento principal del proyecto, estos son Vault para la gestión de secretos de forma segura o Consul para el Service Discovery de los microservicios, así como CloudFormation para la creación de la infraestructura en AWS.
Si deseas conocer más sobre el desarrollo y estructura del proyecto, además de su plan de trabajo y organización puedes explorar los detalles aquí (solo disponible en inglés).
POPBL 2 - ITAPP (Generador de textos)

Este apartado describe el segundo y último proyecto POPBL de la universidad de Mondragón para el máster en Análisis de datos, Ciberseguridad y Cloud Computing. En este caso, fue un tema elegido por el alumnado.
Me gustaría poner en valor el contexto social en el que se realizó este proyecto, ya que fue en pleno confinamiento por la pandemia de COVID-19. Aún así, el grupo se reunió de forma virtual y se organizó para realizar el proyecto y vencer las adversidades que podrían surgir.El proyecto se desarrolló en el contexto de las elecciones presidenciales de EE. UU. en 2020, donde ITAPP (empresa ficticia) ofrecía una herramienta que generaba automáticamente textos personalizados simulando el estilo de los candidatos Donald Trump y Joe Biden.
Esto permitía optimizar el uso de las redes sociales, a pesar del poco tiempo disponible durante la campaña. La aplicación integraba machine learning, gestión automatizada de versiones, medidas de seguridad (como el fuzzing con OWASP Zap) y sistemas para el transporte y almacenamiento de datos (ElasticSearch, Hadoop), con el fin de facilitar el acceso al valor generado por el modelo de forma sencilla.
El diseño de la solución se basó en datos obtenidos de las APIs de Twitter, Tumblr y un conjunto de tuits políticos. Se desarrolló un modelo (con Keras, de forma distribuída con Spark) capaz de generar tweets coherentes a partir de temas introducidos por el usuario en la aplicación ITAPP. El sistema capturaba y limpiaba datos nuevos de forma continua para mejorar el modelo (Spark, Apache Nifi), cuyos resultados se publicaban en la cuenta oficial del POPBL en Twitter.
Se aplicó una metodología CI/CD (Kubernetes, Gitlab CI/CD) con etapas de validación del modelo, análisis estático del código y despliegue sin interrupciones mediante arquitectura Blue-Green. Todo el desarrollo se llevó a cabo siguiendo una metodología ágil.
Si deseas conocer más sobre el desarrollo y estructura del proyecto, además de su plan de trabajo y organización puedes explorar los detalles aquí (solo disponible en inglés).
Gitlab CI/CD
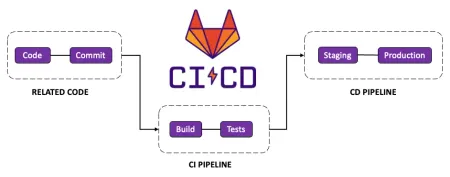
Durante esta práctica del máster de Análisis de Datos, Ciberseguridad y Computación en la Nube, desarrollé una solución completa de integración y despliegue continuo (CI/CD) para un sistema de microservicios basado en contenedores Docker. Todo el trabajo se llevó a cabo siguiendo una metodología Agile, con iteraciones cortas, entregas incrementales y una validación constante mediante tests automatizados.
El objetivo fue automatizar el ciclo completo de testing, empaquetado y despliegue del sistema “Orders”, partiendo de cero. Para lograrlo, diseñé distintos niveles de test (unitarios, de integración, de sistema y smoke), desarrollé una nueva funcionalidad mediante TDD (eliminación de usuarios) y construí un pipeline para Gitlab CI/CD dividido en tres etapas, capaz de generar contenedores versionados y listos para producción.
Uno de los mayores aprendizajes fue entender el valor de testear en etapas, cómo organizar un entorno multi-stage con distintos docker-compose, y cómo asegurar que lo que llega a producción no rompa funcionalidades anteriores. También tuve la oportunidad de trabajar con runners personalizados en GitLab (era un requisito académico) y realizar un despliegue manual en AWS con instancias EC2. En definitiva, fue un proyecto que me permitió tocar todas las piezas del ciclo completo de entrega continua.
Ahora bien, llevé el proyecto a un nivel casi atómico, y esa misma intensidad me permitió ver también sus límites. En un contexto académico, esto fue enriquecedor; pero en el entorno profesional, como me ha ocurrido en ISEA, este nivel de control es raramente necesario (o al menos no me ha ocurrido). Hoy en día, plataformas como Vercel o Render nos permiten externalizar gran parte de este proceso de forma segura y eficiente. Aun así, conocer cómo funcionan por dentro estas herramientas me parece esencial, no solo para cuando se desee profundizar, sino también para entender sus limitaciones.
Este proyecto ha sido una pieza clave para afianzar mis conocimientos de CI/CD, pipelines, testing automatizado y buenas prácticas de despliegue. Una base sólida que ahora sé cuándo aplicar al máximo... y cuándo no tiene sentido hacerlo.
Kubernetes

En esta segunda práctica del máster de Análisis de Datos, Ciberseguridad y Computación en la Nube, me adentré en la gestión de entornos de despliegue orquestados mediante Kubernetes, con el objetivo de automatizar todo el flujo de trabajo de una aplicación basada en microservicios.
Inspirándome en el trabajo previo sobre CI/CD, esta vez el foco se trasladó al diseño de entornos robustos (desarrollo, preproducción, demo y producción), la implementación de una estrategia de despliegue gradual tipo canary, y el uso de Kubernetes como núcleo de la infraestructura. Además, todo el desarrollo se organizó siguiendo una estructura de issues y milestones en GitLab, lo que me permitió estructurar las tareas con un enfoque realista y profesional.
Durante el proyecto, trabajé con herramientas y conceptos clave como:
- ConfigMaps y Secrets para configuración y credenciales.
- Deployments y Pods para lanzar versiones controladas.
- NodePorts y ClusterIP para exposición y conectividad.
- Pipeline CI/CD basado en ramas (dev, canary, master) para automatizar el despliegue según el estado del código.
Preparé un sistema donde solo el código probado y validado por usuarios (vía el entorno canary) llegaba a producción, garantizando así fiabilidad en cada paso. Automatizar el aprovisionamiento del cluster, la carga de configuración y el despliegue de contenedores, tanto en Minikube como en Google Cloud, formó parte esencial del proceso.
Esta práctica me permitió además comprender con claridad conceptos fundamentales para la arquitectura moderna de aplicaciones, como la alta disponibilidad o la escalabilidad horizontal y vertical. Ver cómo Kubernetes permite escalar instancias automáticamente en función de la carga, o cómo se puede garantizar tolerancia a fallos replicando pods, me dio una visión muy valiosa sobre lo que hay detrás de cualquier sistema que se considera “preparado para producción”.
Más allá de lo técnico, esta práctica me ayudó a consolidar mis conocimientos sobre las unidades básicas de Kubernetes y a ganar perspectiva sobre el equilibrio entre control y eficiencia. Tal como reflexioné en la práctica anterior, llevar todo a un nivel tan detallado puede ser muy útil para aprender, pero no siempre es práctico en entornos reales.
En experiencias como la vivida en ISEA he comprobado que en muchos casos es más eficiente delegar parte de esta infraestructura a plataformas como Vercel, que abstraen la complejidad sin perder fiabilidad. Aun así, conocer cómo funcionan estos sistemas por dentro, hasta sus unidades más pequeñas, me ha dado una base sólida para decidir cuándo conviene profundizar y cuándo es mejor abstraer.
Generador de música con Keras
La música ha sido siempre una parte importante de mi vida. Toco el piano desde pequeño, y aunque mi trayectoria profesional gira en torno al desarrollo y la inteligencia artificial, en este proyecto quise explorar un cruce entre ambas aficiones.
El reto planteado fue desarrollar un generador automático de música utilizando redes neuronales recurrentes, concretamente una arquitectura tipo LSTM (Long Short-Term Memory) con Keras, entrenada sobre un conjunto de datos de composiciones de Hans Zimmer en formato MIDI (algunas interpretadas por mí y grabadas mediante GarageBand para MAC).
Aunque el objetivo era generar melodías realistas, el verdadero desafío técnico fue lograr que el modelo aprendiera patrones musicales significativos en lugar de limitarse a repetir secuencias aleatorias. El preprocesamiento fue muy importante: fue necesario convertir los archivos MIDI en vectores representables y codificar correctamente las notas.
Durante el entrenamiento, afiné los hiperparámetros y validé el modelo generando fragmentos de prueba, escuchando cada uno con un criterio tanto técnico como musical. El resultado no es una sinfonía perfecta, pero sí una demostración de cómo la IA puede capturar —aunque sea parcialmente— la estructura de un lenguaje tan abstracto y emocional como la música.
Para cerrar esta sección con un toque más personal, incluyo un pequeño vídeo en el que toco el piano. No se trata de mostrar habilidades musicales, sino simplemente de compartir otra faceta de mí: alguien que, además de disfrutar con la tecnología, también encuentra en la música una forma de divertirse y desconectar.
Si deseas conocer más sobre el desarrollo del proyecto, puedes explorar los detalles aquí (solo disponible en inglés).
Gogoa

En la práctica del desarrollo moderno, herramientas como ChatGPT de OpenAI o GitHub Copilot se han vuelto casi imprescindibles. Lejos de ser una moda pasajera, se han convertido en verdaderos aliados que potencian nuestra productividad, amplían nuestras capacidades y, sobre todo, nos permiten enfocarnos en los aspectos creativos y de alto nivel de cada proyecto. Adoptar estas herramientas no es solo una cuestión de eficiencia: es una forma de evolucionar junto con el entorno tecnológico que nos rodea.
Uno de los proyectos que más ha exigido esta visión tecnológica fue el encargo que recibí para trabajar con los textos de Don José María Arizmendiarrieta, figura clave en la historia reciente de Euskadi y fundador de las cooperativas que hoy forman parte de la Corporación Mondragón. Su pensamiento, profundamente humanista y comprometido con la transformación social a través del cooperativismo, está plasmado en una extensa colección de fichas escritas a mano que, hasta ahora, no estaban clasificadas ni disponibles de forma temática o digital.
El objetivo principal del proyecto es "disponibilizar" esta colección a través de una aplicación web, actualmente en desarrollo, que permita consultar las fichas por temáticas y hacer accesible su legado a investigadores, estudiantes y cualquier persona interesada. Para ello, se han aplicado técnicas de inteligencia artificial tanto tradicionales —similares a las vistas en proyectos como GAIA— como modernas, como los sistemas de recuperación aumentada por generación (RAGs) integrados en ChatGPT.
Durante la fase de desarrollo de los modelos de clasificación —el núcleo técnico del proyecto— nos enfrentamos a varios retos importantes. Uno de ellos fue el claro desequilibrio entre categorías: naturalmente, José María no dedicaba el mismo número de fichas a cada temática. Esta desigual distribución, unida al tamaño reducido del dataset inicial (500 fichas clasificadas por la Asociación de Amigos de Arizmendiarrieta), requería un enfoque sofisticado. Por ello, se aplicaron diversas técnicas de IA para equilibrar el conjunto de datos de entrenamiento, mejorando así la capacidad de generalización y la robustez de los modelos resultantes.
Actualmente, una empresa valenciana especializada está trabajando en la transcripción manual de las fichas manuscritas, y estamos a la espera de recibir ese material para aplicar los modelos entrenados y continuar con el proceso de clasificación automatizada y publicación web.
Elkarbide

Elkarbide es una red social con recorrido, centrada en la difusión de contenidos relacionados con la innovación y el emprendimiento. A través de la plataforma, los usuarios pueden publicar ideas, compartir experiencias y entrar en contacto con otras personas para desarrollar proyectos en colaboración. También se utiliza como punto de acceso a información útil sobre subvenciones públicas, tanto a nivel provincial como nacional, lo que la convierte en una herramienta práctica y valiosa para perfiles muy diversos.
Sin embargo, como ocurre en muchos productos digitales con años a sus espaldas, la interfaz ha quedado obsoleta. La experiencia de usuario ya no responde a los estándares actuales, ni en términos de accesibilidad, ni de diseño, ni de eficiencia. Por ello, se me encargó liderar un proceso de rediseño completo de la plataforma, con el objetivo de modernizarla por completo manteniendo su esencia y funcionalidad.
De momento, ya se ha trabajado en una nueva propuesta visual desarrollada en Figma. El siguiente paso está siendo evaluar qué partes del sistema anterior pueden reutilizarse y cuáles deben replantearse desde cero. Este análisis es una de las fases más críticas en cualquier proyecto: conocer bien el punto de partida y la meta deseada es esencial para poder definir una estrategia realista, tanto en desarrollo de software como en otros ámbitos.
Además de rediseñar la plataforma, este proyecto también es una oportunidad para aprender y probar nuevas tecnologías. La intención es aprovechar el contexto para explorar herramientas y enfoques actuales como React Server Components , que permiten mejorar el rendimiento y escalabilidad de aplicaciones web modernas.
Elkarbide es, en definitiva, un proyecto que combina rediseño, análisis técnico y mejora continua, con el añadido de tener un componente formativo y de investigación que lo hace aún más enriquecedor.
Portfolio
Este portfolio no es solo un escaparate, sino también un proyecto que he desarrollado con criterio técnico y con la intención de que me acompañe a lo largo de mi trayectoria profesional.
Lo construí utilizando Astro, un framework que descubrí expresamente para este proyecto y que me ha parecido una herramienta excelente para crear sitios rápidos, accesibles y fáciles de mantener. Gracias a su enfoque basado en componentes y a la generación estática de páginas, he conseguido una web muy ligera sin renunciar a la estructura ni a la modularidad. Es un buen ejemplo de software bien planteado, centrado en su propósito, sin sobrecomplicaciones.
El desarrollo del portfolio me ha permitido poner en práctica muchos de los conocimientos que he ido adquiriendo con el tiempo: organización clara del código, diseño responsive, navegación fluida o gestión de transiciones. Todo ello está desplegado en Vercel, lo que me permite aprovechar su red de distribución de contenido (CDN) y obtener un rendimiento óptimo, sin complicaciones.
Además de ser mi carta de presentación, este proyecto está pensado para ser escalable y fácilmente modificable. Gracias a cómo está estructurado, puedo añadir nuevos proyectos, experiencias o secciones sin tocar más de lo necesario. A no ser que me dé por rediseñarlo por gusto estético (que todo puede ser 😄), no tengo ninguna necesidad de rehacerlo desde cero.
Actualmente

Actualmente estoy muy centrado en optimizar y refinar mi forma de desarrollar software, no tanto desde la perspectiva de añadir más funcionalidades, sino de mejorar cómo se comportan las aplicaciones que creo: su rendimiento, su carga y su escalabilidad. Aunque ya manejo con soltura muchas herramientas, he detectado puntos de mejora relacionados con la forma en la que se cargan los recursos y se transmite el código al cliente.
Este proceso me está llevando a salir de mi zona de confort y a profundizar en tecnologías más modernas como los React Server Components y el nuevo App Router de Next.js, que estoy explorando a fondo. Al hacerlo, estoy comprobando de forma práctica los beneficios de este enfoque: desde reducir la cantidad de JavaScript que llega al navegador hasta disminuir la dependencia de la red del cliente, lo que se traduce en una experiencia más rápida y robusta.
En paralelo, estoy dedicando parte de mi tiempo libre a investigar cómo portar aplicaciones creadas con Pages Router (basadas en Client Components) al nuevo sistema basado en Server Components. Es un ejercicio técnico muy interesante que me está ayudando a consolidar lo aprendido y a identificar patrones reutilizables en migraciones reales.
A nivel más personal, he retomado con más disciplina tanto la natación como el gimnasio. Siempre he estado vinculado a la natación, pero durante los años de universidad y la pandemia tuve que dejar de lado la preparación de pruebas. Desde hace aproximadamente un año, he vuelto a entrenar con regularidad y con objetivos claros. Ahora mismo, estoy preparándome para participar en el clásico 100x100 que se organiza cada año en Durango, una prueba exigente pero muy motivadora. Y en paralelo, el gimnasio me está ayudando a mantener una rutina estable y a desarrollar una disciplina y compromiso que, sin duda, también se reflejan en mi forma de trabajar.